Chapter 7 Eminent Domain Names
Introduction
All of our discussion thus far has revolved around the idea of using IP address to contact other machines. However, cnn.com isn’t exactly an IPv4 or IPv6 address, but it certainly looks like I can somehow use that sequence of characters to contact another Internet-connected device. Remember, if you know the IP address of CNN.com, you can open it up using a web browser: if you click here, you should be whisked away to CNN’s homepage, despite the fact that your web browser’s address bar has no references to cnn.com. Of course, remembering the words “cnn dot com” is much easier than remembering (and typing) “one five seven dot one six six dot two two six dot two six,” so it’d be ideal to not have to waste brain cells on many sequences of 12 digits.
DNS
The Domain Name System, or DNS for short, is a mechanism for giving more convenient and easy-to-remember names to networked devices. DNS is essentially a massive phonebook distributed across thousands of storage locations around the world. Just like the YellowPages that you wish weren’t still delivered to your front door, each domain name in the DNS phonebook has an associated IP address. Whenever you try to access a domain name, rather than an IP address, your web browser will use DNS to look up which IP address corresponds to the domain you’d like to access. Once the browser has an IP address, our request can proceed in the manner we saw last time! So, DNS is really just another networking layer that makes life a bit easier for us by creating aliases for numeric IP addresses. However, unlike a printed phonebook, changing entries in DNS is pretty simple and relatively fast (and happens all the time!).
In the early days of the Internet, the big phonebook of IP addresses was simply a text file called HOSTS.TXT. Developers would routinely copy some authoritative copy of this text file to their own machines, and only then could they then take advantage of all the domains on the Internet. Remnants of this system still remain even on our modern operating systems. On my Mac (or Linux), I can open up a file called /etc/hosts that lists aliases for IP addresses local to my machine. On Windows, this file is located in C:\Windows\System32\Drivers\etc\hosts, but its contents are the same. On each line, we have an IP address followed by a space and then a domain name. As you might expect, each line is an entry in the phonebook that tells your computer that the given domain name is an alias for the given IP address. Let’s try adding a new entry. 74.125.226.196 happens to be an IP address for google.com, so add the following line to the bottom of your hosts file (you may be prompted for your administrator password, since this is a system file):
74.125.226.196 bing.com
Now, open up a web browser and head to bing.com. Toto, we’re not in Redmond anymore. When you added that line to our local hosts file, you effectively created a new entry in the DNS phonebook (only on your machine, though) that says “bing.com is an alias for the IP address 74.125.226.196.” So, when your web browser saw “bing.com,” it was told that that domain resolved to 74.125.226.196, one of Google’s IPs, which led you to Google’s homepage. In the same way, google.com or any other domain is simply a readable alias for an IP address.
DNS Hierarchy
Given the massive size of the Internet, it’s probably not the best idea to keep a list of every single domain name on the Internet in a single text file. Not only would it be impractical to keep the billions of people on the Internet up-to-date with the latest version, but if that single file were ever compromised, someone could wreak havoc on the Internet as we know it. For reasons like these, it makes more sense to distribute the mapping of domains to IP addresses across multiple machines, called DNS servers. Rather than keep track of the entire domain name space, each DNS server typically maintains only a small subset of all the domains that have been registered on the Internet and their corresponding IP addresses.
Let’s come back to that request to CNN.com we talked about last time and take a look at how your computer resolves the domain name “cnn.com” to the IP address of a web server. First, my browser will probably check its cache of recently-accessed domain names to see if it already knows the IP of cnn.com, perhaps because I’ve accessed it recently. If the browser doesn’t already know the IP address of cnn.com, it will then contact a cache DNS server to ask which IP the domain points to. This DNS server is likely managed by my ISP, which remember, is the company responsible for connecting me to the Internet. My computer was informed of the IP addresses of these servers when I first joined the network, since without any DNS servers, I’d be unable to browse any sites without knowing their IP addresses. On a Mac, I can view the IP addresses of these DNS servers (as well as change them if I know the IP addresses of any other DNS servers) in my network settings, as shown below. Alas, I digress. Because lots of people are making requests to the same DNS servers, there’s a good chance that a cache DNS server is going to be asked for the IP address of a popular site like “google.com” pretty frequently. So, cache DNS servers will remember some number of recently-accessed domains in order to provide answers to clients quickly. But, in the event a cache DNS server doesn’t already know the IP address for a domain, then it’s going to have to ask some other DNS servers for the answer (and then perhaps remember it for a while).
If the cache DNS server knows where “cnn.com” is, perhaps because another computer on the network made a request to cnn.com a few minutes ago, it will respond immediately with the domain’s IP address, and my browser be good to go. But because that makes the story boring, let’s assume the first DNS server we contact doesn’t know the IP address of cnn.com. Now, perhaps after asking a few nearby DNS servers and getting nowhere, our poor DNS server will go ahead and contact a root DNS server. Root DNS servers are located all around the world (click here for a complete list) and for a critical part of the Internet’s infrastructure. The root DNS server will forward the request along to one of many TLD DNS server, responsible for handling all requests for a particular TLD. A TLD, or top-level domain, is a domain’s suffix, like “.com” or “.net”. Because I’m looking for the IP address for cnn.com, my request will be sent along to a .com TLD DNS server. While the TLD DNS server doesn’t know exactly what the address of cnn.com is (damn!), it does know the right person to ask. The TLD DNS server will proceed to query the authoritative name server for cnn.com, which is responsible for maintaining a list of IP addresses for all addresses in a DNS zone, or group of domains. Finally, this server can respond with the IP address for cnn.com, which will finally make its way to my web browser. Phew! All of this before my computer even started to request the daily news!
Let’s take a more concrete look at the process of resolving a domain name with an example. If we head here, we can actually see the servers involved in looking up the IP address of the domain name cnn.com. This particular tool doesn’t happen to be using any DNS caching servers, so the first request goes straight to a root DNS server. First, my request went to the root DNS server at k.root-servers.net, which has the IP address 193.0.14.129. The root DNS server will then send my request to a TLD DNS server responsible for the .com TLD, one of which has the IP address 192.52.178.30. Next, the request will be forwarded to an authoritative DNS server for cnn.com, like the DNS server at ns3.timewarner.net, which has the IP address 199.7.68.238. Finally, this DNS server will return the IP address for cnn.com, which will make its way back down this hierarchy to my browser.
To recap, resolving a domain name looks like this:
-
Browser checks the hosts file and cache. An IP address may be returned.
-
Browser makes a request to a cache DNS server. An IP address may be returned.
-
Cache DNS server makes a request to a root DNS server.
-
Root DNS server makes a request to a TLD DNS server.
-
TLD DNS server makes a request to authoritative name server.
-
Authoritative name server responds with an IP address.
DNS Hijacking
Sometimes, the domain that we typed into our web browser’s address bar hasn’t been registered by anyone, so it doesn’t actually point any IP address. If this is the case, then the gods of the Internet (the individuals governing and writing the standards that describe how devices should operate on the Internet) have decreed that your web browser should display some kind of message letting you know that the domain you’re looking for isn’t owned by anyone yet. However, it turns out that many ISPs don’t exactly listen to to the gods of the Internet. Instead of letting your web browser tell you that a site doesn’t exist, an ISP may instead redirect you to a page that looks something like this:
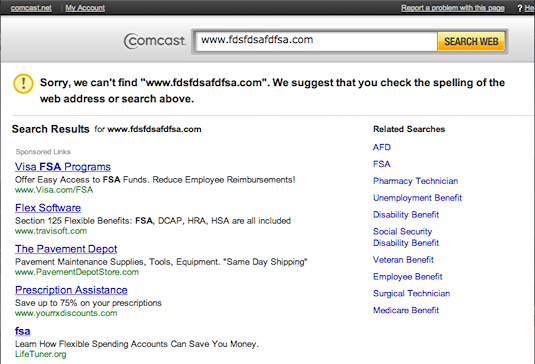
Why might your ISP want to do this? $$$! As you can see from this picture, this page you land on could contain advertisements from a number of different companies that paid your ISP to feature their clever adverts. Issues like this are part of a larger debate referred to as net neutrality. Essentially, the questions behind net neutrality ask what degree of control your ISP should exercise over your Internet connection. For example, rather than charge you one, flat rate to access the Internet, ISPs could instead create a tiered model where you pay for access to certain sites. As shown in the below (currently) fictional advertisement, you could pay $5/month to access search sites like Google and another $5/month to access news sites like CNN. While ISPs might advocate this kind of pricing scheme, others want the Internet to remain a more free environment where newer, smaller companies aren’t put at any disadvantage to tech giants as a result of tiered pricing. Debates like these are currently ongoing in governments around the world, and at least right now, there isn’t a straightforward answer!

On a similar note, even a distributed system like DNS could still be compromised. If this were to happen, then an attacker could tamper with the IP addresses pointed to by various domains, which would be pretty bad news for aspiring YouTube celebrities everywhere. So, a few years ago, ICANN, the organization responsible for assigning domain names, bestowed upon seven heroes the keys to the Internet. When all seven individuals, scattered across the globe in the US, UK, Burkina Faso, Trinidad and Tobago, Canada, China, and the Czech Republic, come together as one superpower, the Internet can be rebooted and rid of all evil. You might think I’m joking, but this actually isn’t too far from the truth. In fact, DNSSEC, or DNS Security, is an emerging standard that seeks to make DNS more secure in general by ensuring that attackers can’t forge the IP addresses of websites.
DNS Records
While the first HOSTS.TXT file simply stored a series of mappings between IP addresses and domain names, modern DNS servers actually store a bit more information. Today, most domains have the equivalent of a spreadsheet associated with them. Here’s some of the information that’s currently associated with cse1.net.
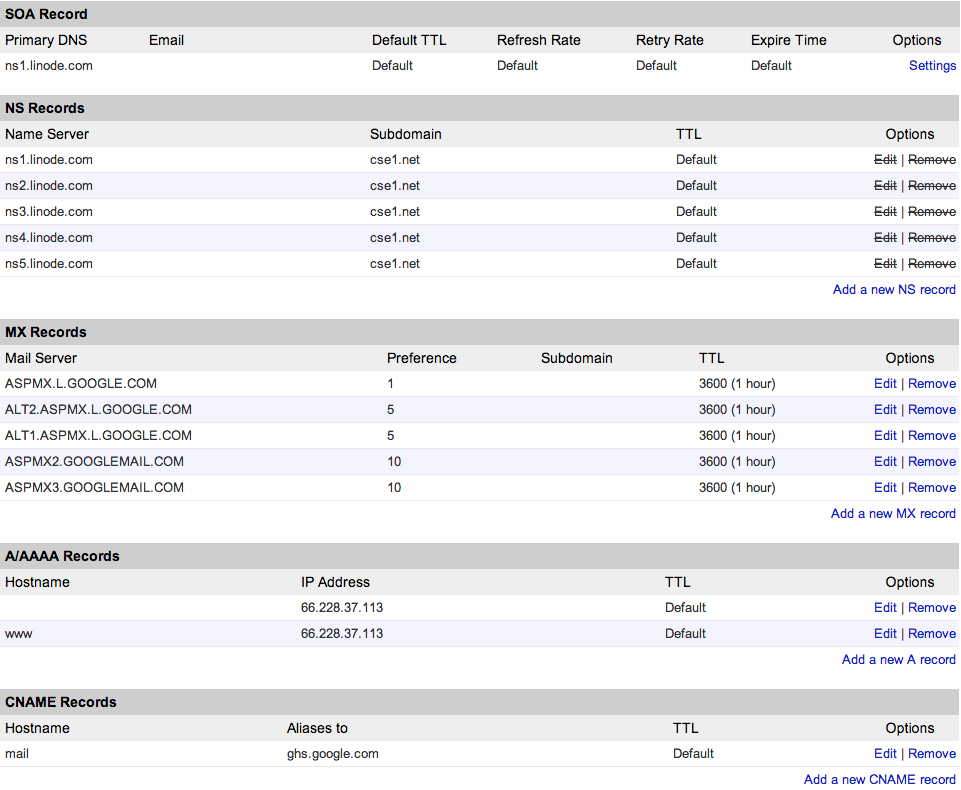
Each row in this table is called a DNS record, and it’s actually stored in a text file called a DNS zone file stored somewhere on my web server. As you can see, the DNS phonebook can have a few different types of entries. Each of these rows also has a TTL, or time-to-live, which defines the amount of time that should pass before the record should be refreshed by a DNS server. Here are a few types of DNS records:
-
SOA record. The start of Authority record specifies the authoritative information about the zone, including the primary name server.
-
NS records. Name server records specify additional name servers for the zone. That way, if a particular name server isn’t responding, my site can have a few backup plans.
-
MX records. Mail eXchange records specify how email sent to the domain should be handled. Using MX records, I can set up email addresses using my domain.
-
A records. A records are the bread and butter, as they specify which IP address the domain points to. When we edited the hosts file a few sections ago, we essentially created an A record for
bing.com. Here, we can see that both cse1.net and www.cse1.net point to the same IP address, which effectively makes typing the “www” part of the website’s address optional. -
AAAA records. AAAA records are identical to A records, but AAAA uses IPv6 while A uses IPv4. Remember the difference?
-
CNAME records. Canonical name records allow domains to be aliased to other domains. Here,
mail.cse1.nethas been aliased toghs.google.com, which means that a request tomail.cse1.netwill simply be sent to one of Google’s servers instead. I could have also looked up the IP address forghs.google.comand created an A record to accomplish the same thing, but using a CNAME record instead means that Google can go ahead and change the IP address ofghs.google.comat any time, and I won’t be affected.
TLDs
Let’s come back to TLDs, which we touched on a bit earlier. We saw that every domain is in the form domain.tld, where the TLD, or top-level domain, comes from a list of about 250 suffixes approved by the Internet Assigned Numbers Authority (IANA). Domains also may be divided into separate components called subdomains. For example, in the address foo.example.com, we’d say that foo is a subdomain of example.com. Subdomains can be any number of levels deep, so foo.bar.example.com is also a valid domain. Using DNS, I can assign different IP addresses to different subdomains of the same domain name by creating new A records or CNAME records in my DNS zone file. That way, mail.example.com might point to Gmail while files.example.com could point to Dropbox.
Here’s a list of some common TLDs and their intended usages. However, today people often purchase TLDs based on what’s available or aesthetically pleasing, as some TLDs have no restrictions on who can purchase them and how they can be used. If I wanted the domain “example” but “example.com” was already taken, then I might instead purchase “example.net” or “example.org,” even if I don’t intend to use the domain to create a “network,” which is the intended usage of the “.net” TLD! While anyone can buy a “.com,” “.net,” or “.org,” some TLDs cannot simply be purchased by anyone on the Internet.
| TLD | Intended Usage | Open to anyone? |
|---|---|---|
| .com | Companies | Yes |
| .edu | Educational institutions | No |
| .gov | US government entities | No |
| .info | Information | Yes |
| .mil | US military organizations | No |
| .net | Networks | Yes |
| .org | Organizations | Yes |
The IANA also defines a list of TLDs based on country codes, called ccTLDs. While these are meant to give countries their own little piece of the domain namespace, many people take advantage of country codes to create cute domain names. For example, the ccTLD for Libya is “.ly,” which is used by URL-shortening services like bit.ly and owl.ly. There’s also “.me,” the ccTLD assigned to Montenegro, which is cleverly used by sites like about.me, which allows you to create your own home page. Even the United States’ own ccTLD, “.us,” has been put to good use by sites like del.icio.us. I’m also proud to say that my initials are a valid TLD, thanks to Turkmenistan. However, since ccTLDs are managed by individual countries, real-world politics can sometimes oddly come into play. Recently, a tech startup (then) called Art.sy had to change domains because of a conflict in Syria! You don’t see that one every day.
Country code TLDs are nice, but they’re still a bit limiting in terms of the domains companies can create. To solve this problem, the IANA is considering introducing a new set of between 100–3000 TLDs based on an application process. For a cool $185,000, you can apply to create your very own TLD, though the IANA estimates that these new TLDs won’t be created until the end of 2013 due to possible trademark concerns. However, if the application for a TLD is granted, then the organization that applied will have full control over who can and can’t use the TLD. ICANN’s website has an up-to-date list if you’re curious what’s already been applied for!
Purchasing a domain is actually pretty easy (and inexpensive!). To do so, all you need to do is head to a domain name registrar like GoDaddy, Namecheap, or Network Solutions. These companies handle paperwork and interfacing with ICANN, the non-profit organization responsible for managing the huge number of registered domain names, among other things. Domains typically cost between $10–$15 per year to maintain, which I think is a pretty reasonable price for carving out your own little place in the Internet. While some registrars may include some number of email addresses on the domain your purchased, simply buying a domain name is separate from creating a website. After all, we now know that a domain name is simply an alias for some IP address, which by nature has to be attached to some Internet-connected and publically-accessible device! Unfortunately then, hosting a website usually incurs a monthly cost to rent some hardware in addition to the annual fee associated with a domain name, but such is life on the Interwebs. More on hosting your own website later, though!
URLs
What we see in our web browser’s address bar is often much more than simply a domain name. Usually, we locate pages on the Internet using URLs, or uniform resource locators. As its name suggests, the goal of a URL is to identify a specific resource on the Internet. cnn.com is one website, but it contains many different resources, like the home page, sports page, weather page, and so on. Each news story on CNN (which has a unique URL) can also be considered a resource, and so can the various images that appear on the page, since they too can be accessed via a URL. The word “resource” sounds a bit abstract at first, but you can think of a resource as something that you want to access on the Internet, whether that be a video of a cat or a web page of cat facts.
URLs have a few different pieces, and a canonical URL looks something like this: scheme://username:[email protected]:port/path?query_string#fragment_id. Let’s take a look at the different parts of a URL.
-
Scheme. The scheme describes the format in which information will be transferred between your computer and the machine responding to you. A scheme called HTTP, which we’ll see in much more detail in the next section, is currently hte most common, but you also might run into some URLs using FTP. The scheme is followed by a colon and two slashes.
-
Username and Password. Using a technology called basic auth, some sites that require a login allow you to put your credentials right in the URL. Not all sites support this feature, though, so you can’t just put your username/password combo in any URL and expect it to work. A colon separates the username and password, and the password is followed by an @ character.
-
Domain. Next up is the domain, which is simply an easier-to-remember alias for a numerical IP address.
-
TLD. All domains end in a TLD, and a dot separates the domain name from its TLD.
-
Port. When contacting a server, you can also specify a port number to contact a specific service on the server. More on these in the next section! The port is prefixed with a colon.
-
Path. The path identifies which resource on the server you’re looking for. Slashes are typically used to create hierarchy among resources.
-
Query String. The query string allows additional information to be sent to the server. Typically, the query string consists of key-value pairs, where a single pair associates a value with some identifier for the value. For example, a key-value pair like “foo=bar” says that I want to send along the value “bar” in the URL, and whoever is responding to my request can access the value with the key “foo.” The query string starts with the ? character, and the & character separates key-value pairs.
-
Fragment. The fragment provides some additional information that can be used by the web browser. This information isn’t sent along to the server, so it can be used only by the client. The fragment is prefixed with the # character.
More concretely, a URL with all of these parts might be: http://tommy:[email protected]:80/news/story.html?wolf=blitzer#situation. Let’s label the terms we just saw:

You may also have heard the term URI used to describe what you type into your web browser’s address bar. Though the two terms are commonly conflated, URIs and URLs are actually different things. URIs, or uniform resource identifiers, are actually more general than URLs, as they serve simply to identify something, not necessarily locate something. The “L” in URL does indeed stand for “locator,” and that’s because the purpose of a URL is to describe how to find some resource on a network. In doing so, a URL can also serve as a URI for that resource, since we can say that a resource’s location identifies it. For example, saying that my name is “Tommy MacWilliam” identifies me, but it doesn’t give any information about how to locate me. On the other hand, the address “33 Oxford St., Cambridge, MA, USA, Planet Earth” both describes the location of a building and identifies it (since there is one building with that address). So, a URL is also a URI, but a URI isn’t necessarily a URL. If you head to your local library or bookstore, you can also find an example of something that is a URI but not a URL: ISBN numbers. If unfamiliar (because who reads books anymore anyway?), an ISBN is a unique number assigned to published books; an ISBN for one of my favorite books, Alice’s Adventures in Wonderland, is 9780811822749. Formally, this is called a URN, or uniform resource name, and is officially expressed as urn:isbn:9780811822749. Again, this ISBN number certainly identifies this great book, but it doesn’t tell you where you can go buy it.
Sounds like URIs are kinda abstract, so let’s come back to URLs, since you probably type those into the address bar of your web browser every day. We said earlier that an image and a news article examples of resources, but many URLs don’t actually map to a file on disk. For example, a URL might be part of a web API, or application programming interface. “API” is a pretty common buzzword (though I guess it’s not really a word) in the tech world today, and an API (in the context of web applications, anyway) is simply a way of exposing information via a standardized structure of URLs. By creating an API, or a set of URLs other people can access, a site can make information available dynamically. Facebook, for example, has an API that allows you to get information from users’ Facebook profiles, and Google has APIs that allow you to access your events on Google Calendar or search YouTube.
Let’s take a look at an example of an API. The MBTA (the organization that runs the Boston subway system, if unfamiliar), has a cool API that makes real-time train information available. For example, if you head to this URL, you can see a live schedule for the red line, one of Boston’s train lines. However, this page doesn’t look as shiny as a Google Map showing train locations. Instead, this data is formatted as JSON, which is a standardized, machine-readable encoding of information. Now, other software developers can use this information to build cool apps! While this URL might point to an actual file called “red.json” somewhere on an MBTA server, since the positions of trains are constantly changing, there’s a good chance that this URL is more dynamic than simply a static file. A bit later, we’ll see how this might actually be implemented!
Browser Requests
Alright, let’s take a step back and tie together what we’ve seen in the past couple sections. When we make a request to a web page like CNN, we probably do so using its domain name, cnn.com. So, the first thing your web browser needs to do is figure out which IP address corresponds to cnn.com. This is where DNS comes in. Your web browser will make a request to the IP address of a DNS server, which may or may not know the IP of cnn.com. If it doesn’t, then it will ask a root DNS server, which will then query a TLD DNS server, which will forward the request along to an authoritative name server that knows the IP address for cnn.com. This response will eventually make its way back to your web browser. Now that your web browser has an IP address, it’s ready to request some data. However, your computer isn’t directly connected to the computer behind that IP address. Instead, the request will be forwarded along to a router on the same network as your computer. This router probably doesn’t know where cnn.com is, but it has an entry in its routing table that tells it where the next nearest router is. So, the router will forward the request along to a router that is closer to the final destination, and eventually, your request will complete its trip!
In the next section, we’ll see how exactly your request is sent, as well as how sites like cnn.com know what you’re looking for!